はじめに
コンピュータビジョン分野においてTransformerを活用した有力なモデルであるSwin Transformerについて勉強しようと思い、今回の記事にまとめました。
まず基本となるTransformerおよびVision Transformerについておさらいし、その後Swin Transformerについて記載します。
Transformer
背景
Transformerは2017年に翻訳タスク用に提案されたネットワークです。
Transformer以前は、翻訳などの言語処理を行うモデルとしては再帰的な構造を持つネットワークであるRNN(LSTM, GRU等)がよく使われていました。
しかしこれらのモデルでは単語を逐次的に入力していくため並列処理ができず、学習時間が長いという欠点がありました。そのため、巨大で複雑なモデルを構築して高度な言語処理を行うことは難しかったとされています。
また、RNNではなくCNNベースのモデルを言語処理タスクへ応用する研究もされていました。CNNの場合は逐次処理ではなく文章を一度に処理できるため学習は高速化できましたが、文章が長くなると離れた単語同士の関係性を考慮できないという課題がありました。
これらの問題を改善したのがTransformerです。
TransformerではRNNやCNNは使われておらず、"Attention"(注意機構)が主役のネットワークになります。
構造
Transformerの構造は以下の通りです。(論文より引用)
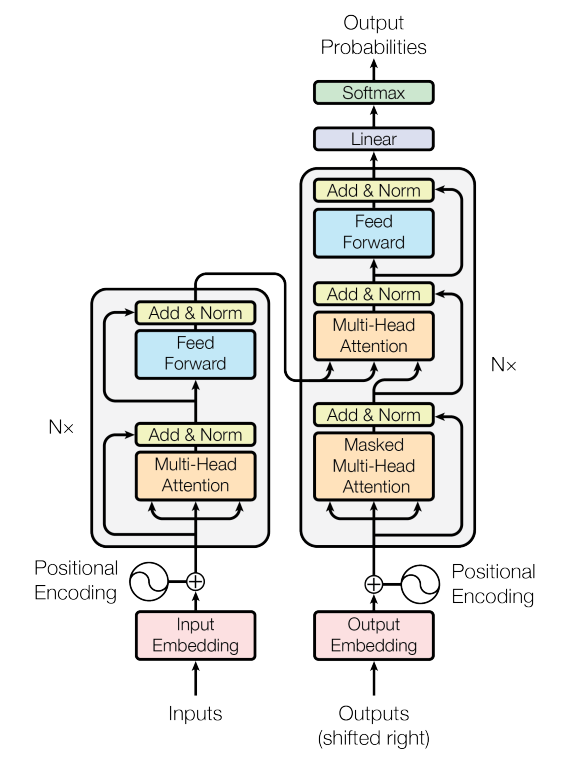
主な特徴としては、
- エンコーダ-デコーダモデルである (左側がエンコーダ、右側がデコーダ)
- 入力データはEmbedding層により単語ごとにベクトルに変換され、Positional Encoding*1を経てTransformer blockに入力される
- "Multi-Head Attention"*2を繰り返し実施
エンコーダ側ではself attention、デコーダ側ではmasked self attention*3とsource-target attentionを行う
発展
Transformerは翻訳タスクで当時のSoTAを達成しました。
その後もTransformerをベースとした手法(BERT, GPT-nなど)が次々と発表され、自然言語処理分野における主流になりました。
また自然言語処理以外でも、音声認識や音楽生成などへの応用も研究されるようになりました。*4
そしてコンピュータビジョン領域にもTransformerを適用しようという研究が活発化し、その代表的な物がVision Transformerとなります。
Vision Transformer(ViT)
概要
Vision Transformer(通称ViT)はTransformerを画像分類タスクに適用したものです。
それ以前の画像認識モデルにおいてほぼ必須であったCNNを使わずにSoTAを更新したことで大きなインパクトを与えました。
ネットワーク構造としてはTransformerのエンコーダをほぼそのまま使っています。

元々のTransformerが単語の列を処理するのに対し、ViTでは入力画像を小さな「パッチ」に分割し、各パッチを単語のように扱うイメージになります。
- それぞれのパッチをベクトル化(flatten)して埋め込みを行い、位置エンコードを加えてTransformerエンコーダに入力
- エンコーダの中の処理は本家のTransformerとほぼ同様
細かい点として、正規化層がMulti-Head Attentionより前に来ていること、MLPの活性化層にReLUではなくGELU*5を用いているといった差はある
性能について
論文のTable 2に示されているように、画像分類用の多くのデータセットにおいて、
当時のSoTAモデル(CNNベース)より高いスコアを記録しました。
またViTの特徴としてJFT-300M*6などの巨大なデータセットで事前学習させているという点があります。
事前学習用のデータセットが小規模の場合はむしろ既存のモデルより性能が低いが、巨大なデータセットを使うことでその真価を発揮することが示されています。
Swin Transformer
概要
ViTは画像分類で優れた結果を出しましたが、コンピュータビジョンにおける様々なタスクにTransformerを適用するためにはまだ次のような問題がありました。
- 画像を固定サイズのパッチに分けて入力するだけだと、物体のスケールの変化に対応するのが難しい (物体検出タスクなど)
- 全てのパッチ間で関連度を求めるため、サイズの大きい画像では計算量が大きくなりすぎてしまう
これらの問題を解決し、コンピュータビジョンの様々なタスクに使える汎用的なバックボーンとして提案されたのがSwin Transformerです。
Swin TransformerではViTから以下のような改善が行われています。
- 階層的構造("パッチマージ"を繰り返して特徴マップを小さくしていく)により、マルチスケールの特徴を得る
- "Window"でパッチをグループ分けし、各Window内でパッチ間の関連度を求めることで計算量を削減
(以下は論文Figure 1から引用)

構造と特徴
Swin Transformerのネットワーク構造を以下に示します。

上図の(b)に示されているように、Swin Transformer Blockの中身はViTのアーキテクチャとほぼ変わりません。
異なるのはW-MSA(Window-based Multi-head self-attention)とSW-MSA("Shifted" W-MSA)です。これらの"Window"のイメージは以下になります。

この図のように、パッチをMxMのwindowで分けて各window内でattentionを計算するのがViTとの違いです。
- ViTの場合
全パッチ間でattentionを計算するため、この部分の計算量は以下のようにパッチ数の2乗に依存する。(パッチ数[h x w]個とする) - Swin Transformerの場合
MxMのwindow内でattentionを計算するため、以下のようにパッチ数に対し線形となる。
このようにwindow-basedにすることで計算量は削減されますが、本来は隣接していて関連度の高いパッチ同士がwindowで分割され、これらのパッチ間での関連度が無視される可能性があります。
そこで、W-MSA(上図の左)とSW-MSA(上図の右)を交互に用いることで隣接するwindowに属するパッチ間の関連度も考慮されるようにしています。(この効果はTable 4に示されています)
性能について
論文中では、画像分類に加えて物体検出とセグメンテーションにおいても優れたスコアが示されており、Swin Transformerが様々なCVタスクに適用できる汎用的なバックボーンであることが主張されています。
まとめ
今回の記事作成を通して、TransformerからSwin Transformerまでの流れを自分の中でざっと整理することができました。
Swin Transformerの登場でTransformerの利用がより身近になったことで、CNNベースモデルの出番は今後減っていくのでしょうか...。
論文リンク
- Transformer
Attention Is All You Need - Vision Transformer
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Swin Transformer
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
*1:Positional Encodingは、単語位置に一意の値を加算することで"単語の順番"が無視されないようにする役目
*2:Multi-Head Attentionは、query、key、valueをそれぞれheadの数に分割し、パラレルにattentionを計算してから結合するモジュール。複数のheadに分けてattentionを実施する方が、分けない場合より性能が上がったと報告されている。
*3:"masked"は、デコーダがある位置の単語を予測する時にそれより未来の単語をマスクしてカンニングを防ぐため。
*4:音声認識分野への応用例としては、「Conformer」や「wav2vec 2.0」などがある。
音楽生成への応用の一例としては「Music Transformer」がある。これは、曲の途中までを入力して続きを予測して生成したり、指定したメロディに対して伴奏を生成したりできる。
*5:GELU(Gaussian Error Linear Units)は標準正規分布を利用した活性化関数。ReLUを滑らかにしたような形。GPTやBERTでも使われている。